
The Stable AI team is proud to present Stable Audio 2.0, a groundbreaking achievement in AI-generated audio. This version establishes a new benchmark by producing high-quality, full tracks with coherent musical structures up to three minutes in length at 44.1kHz stereo.
By integrating audio-to-audio generation, Stable Audio 2.0 empowers users to upload and transform samples using natural language prompts. The model’s training was conducted exclusively on a licensed dataset from the AudioSparx music library, with a commitment to honoring opt-out requests and ensuring fair compensation for creators.
The Evolution of Stable Audio
Building on the success of Stable Audio 1.0, which was launched in September 2023 as the premier commercially viable AI music generation tool capable of creating high-quality 44.1kHz music, Stable Audio 2.0 introduces enhancements that redefine the scope of text-to-audio and audio-to-audio capabilities.
This latest model allows users to upload audio samples and transform them through natural language prompts, offering an expanded suite of sound effect generation and style transfer features. This progress not only augments the creative toolbox for artists and musicians but also enriches the entire creative process.
Key Innovations in Stable Audio 2.0
Full Length Tracks
Stable Audio 2.0 differentiates itself from other cutting-edge models by its ability to generate songs up to three minutes in length. These are not just any songs, but compositions with structured arrangements that include introductions, developments, outros, and even stereo sound effects.
Audio-to-Audio Generation
A pivotal update is the model’s support for audio file uploads, which enables the transformation of ideas into fully produced samples. Moreover, to ensure ethical use and compliance with copyright laws, the Stable AI team employs advanced content recognition technology.
Expanding Creative Possibilities
Stable Audio 2.0 enriches the production of sound and audio effects, offering artists new avenues to enhance their audio projects.
Moreover, the introduction of style transfer allows for the customization of audio outputs to match specific project themes and tones. This seamlessly integrating newly generated or uploaded audio within the generation process.
The Technology of Stable Audio 2.0
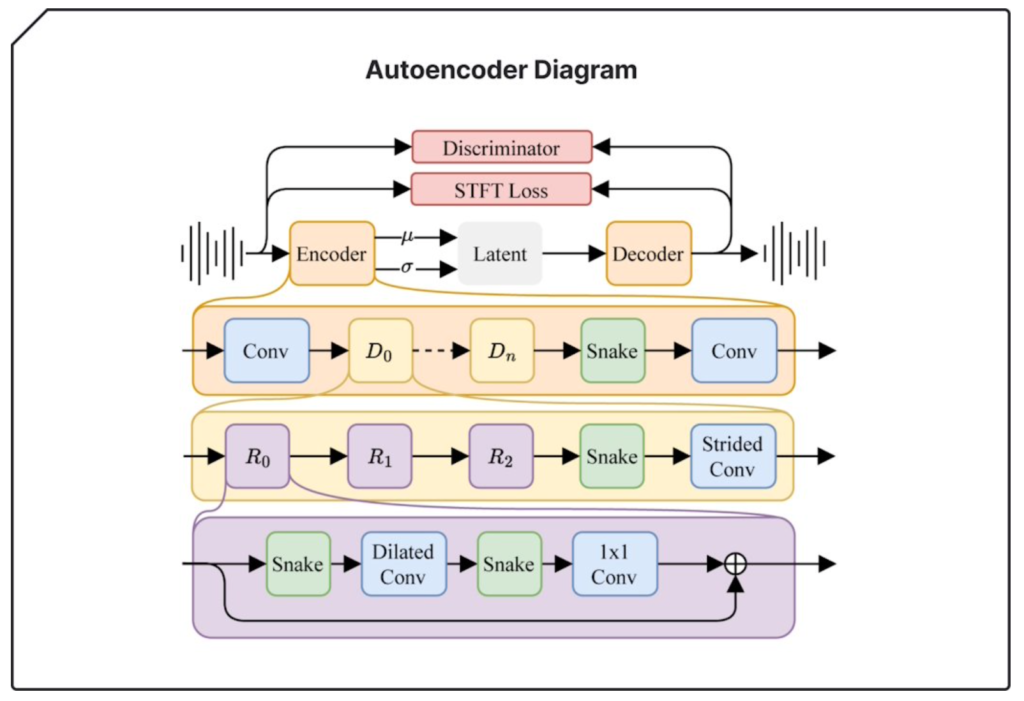
The architecture of Stable Audio 2.0’s latent diffusion model is meticulously designed to enable the generation of full tracks with coherent structures. By refining system components for optimal performance over extended durations, the model incorporates a highly compressed autoencoder and a diffusion transformer (DiT), showcasing improved capability in recognizing and replicating the essential large-scale structures of high-quality musical compositions.
Commitment to Ethical AI Use
In line with the ethical standards set by its predecessor, Stable Audio 2.0 is trained on a vast library from AudioSparx, ensuring respect for copyright and creator rights. Also, by partnering with Audible Magic, the Stable AI team continues to prioritize copyright protection through advanced content recognition technology.
Stay connected for the forthcoming release of the research paper, which will delve deeper into the technical advancements of Stable Audio 2.0.
Read other articles in our Blog.