
The evolution of audio synthesis technology has reached a new milestone with the development of Stable Audio 2.0. This innovative approach leverages latent diffusion models to generate long-form, high-fidelity stereo audio from text prompts. This paper delves into the mechanics of this system, showcasing its efficiency and the revolutionary step it takes beyond its predecessors.
Stable Audio 2.0 operates at an impressive 44.1 kHz, a standard for high-quality audio. It incorporates a fully-convolutional variational autoencoder (VAE) to efficiently handle this high resolution. This setup allows the system to generate audio up to 95 seconds long in just 8 seconds on advanced GPU architectures. Such performance not only demonstrates the system’s rapid response rate but also its ability to handle professional-grade audio tasks.
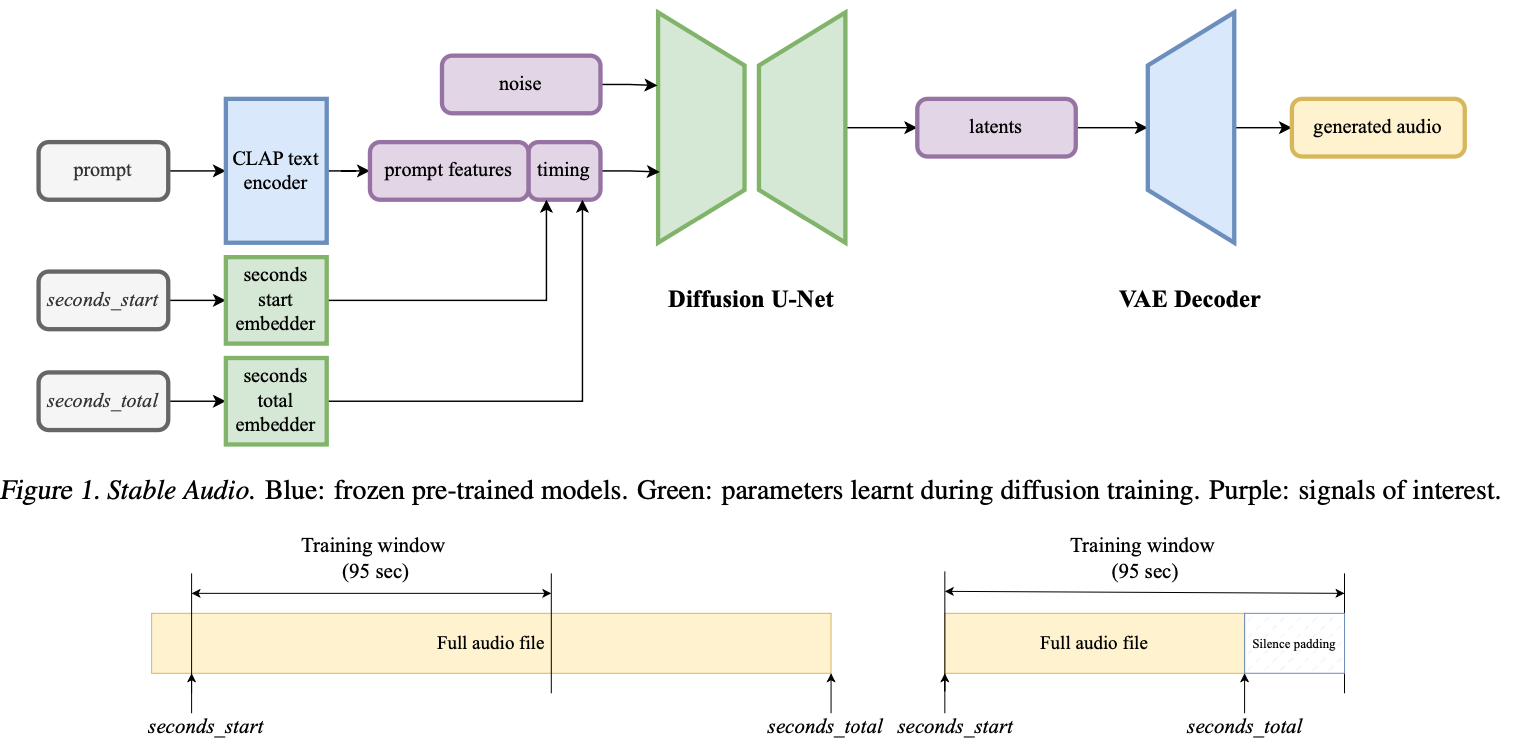
Moreover, the introduction of timing embeddings enables precise control over the length and timing of audio outputs. This feature is essential for applications requiring sync with visuals or other audio tracks, making Stable Audio 2.0 particularly valuable in multimedia production environments. The system’s architecture is designed to optimize computational resources while delivering audio quality that rivals the best in the industry.
Technical Foundations of Stable Audio 2.0
At the core of Stable Audio 2.0’s efficacy is its advanced latent diffusion model. This model builds on the concept of latent space manipulation, where audio data is compressed into a lower-dimensional space before being processed. This approach significantly reduces computational overhead while preserving the nuances of the original audio signal.
The model’s backbone, a fully-convolutional VAE, plays a critical role in this process. It compresses stereo audio into a latent representation that the diffusion model then uses to generate output. The VAE’s architecture, designed specifically for audio, ensures that even at high compression ratios, the audio quality remains uncompromised. This balance between performance and efficiency is one of the key innovations of Stable Audio 2.0.
Conditioning on text and timing further refines the output. The system uses CLAP (Contrastive Language-Audio Pretraining) text embeddings to understand and interpret the textual prompts. These embeddings help guide the generative process, ensuring that the resultant audio not only sounds plausible but also aligns well with the input text’s semantic content.
Performance and Applications
In practical terms, Stable Audio 2.0 sets a new standard for text-to-audio synthesis. The model’s ability to generate structured, variable-length audio makes it a powerful tool for creating music and sound effects that are tailored to specific requirements. This capability is particularly important in industries like film and gaming, where audio often needs to match specific scenes or actions.
Benchmark tests have shown that Stable Audio 2.0 performs exceptionally well across various metrics, including the Fréchet Audio Distance and the Kullback-Leibler divergence.
To fully leverage the capabilities of Stable Audio 2.0, it is essential to understand its applications across various scenarios. Industries such as virtual reality, podcasting, and automated dialogue replacement for film could see transformative changes with the adoption of this technology. The system’s ability to generate realistic and contextually appropriate audio from simple text prompts can significantly streamline the creative processes in these fields.
Moreover, the educational and accessibility sectors could also benefit from Stable Audio 2.0. For example, creating audio books or learning materials with tailored audio descriptions can now be done quickly and effectively, enhancing the learning experience for visually impaired students or providing additional auditory learning support for students who benefit from audio reinforcement.
Advanced Features and Metrics
Stable Audio 2.0 not only excels in speed and efficiency but also in its application of advanced audio synthesis features. The system employs sophisticated metrics such as the Fréchet Audio Distance, which evaluates the similarity between generated audio and a large corpus of real audio data, ensuring the outputs are realistic and coherent. The Kullback-Leibler divergence is another metric used to measure the semantic accuracy of the audio relative to its text prompt, confirming that the generated sounds are true to the descriptions provided.
Furthermore, the inclusion of timing embeddings allows for precise control over the duration and sequence of sounds. This feature is critical when creating audio that needs to sync with other elements in multimedia projects. The ability to adjust the timing of audio on the fly, without compromising quality, is a breakthrough in audio production technology.
Community and Developer Support
Stable Audio 2.0’s development team has committed to supporting a growing community of users and developers. Through comprehensive documentation, open-source tools, and active community engagement, the team provides resources that facilitate the adoption and application of this technology. This support extends to educational workshops, detailed API documentation, and a robust forum where users can share tips, ask questions, and provide feedback on the system.
This collaborative approach not only enhances user experience but also accelerates the improvement and evolution of Stable Audio 2.0. By embracing community insights and challenges, the development team can address real-world application hurdles, ensuring the system remains at the forefront of audio synthesis technology.
Looking Forward
The future of Stable Audio 2.0 appears promising, with ongoing research and development focused on expanding its capabilities. Potential upgrades include improved language understanding for more nuanced audio generation and expanded training datasets to cover a wider array of sounds and music genres. These improvements aim to make Stable Audio 2.0 even more versatile and capable of handling an even broader range of audio synthesis needs.
As we look to the future, the potential for integrating Stable Audio 2.0 with other AI technologies, such as video generation and virtual agents, could offer even more immersive and interactive multimedia experiences. The intersection of these technologies presents exciting opportunities for creating fully automated, high-quality media content that is both scalable and cost-effective.
Conclusion
Stable Audio 2.0 is not just a tool; it’s a revolutionary step in digital audio technology. Its impact extends beyond traditional music and sound effects creation, offering vast potential for innovation in multimedia, education, and accessibility. As this technology continues to evolve, it will undoubtedly play a pivotal role in shaping the future of audio production.
For those who wish to explore the full capabilities and technical details of Stable Audio 2.0, the complete paper is available for review. Access to the paper can provide further insights into the sophisticated architecture and advanced features that make Stable Audio 2.0 a leader in audio synthesis technology. You can find the full paper here, providing a comprehensive understanding of this cutting-edge technology.
Read related articles: