-

Stable Audio 3.0
Key Takeaways Stability AI excited to announce the launch of Stable Audio 3.0, a model that produces high-quality, full-length tracks with coherent musical structures up to three minutes long at 44.1 kHz stereo, all from a single natural language prompt. This new version extends beyond text-to-audio capabilities, now including audio-to-audio functionality. Users can upload audio…
-

How to use Stable Audio Open 1.0
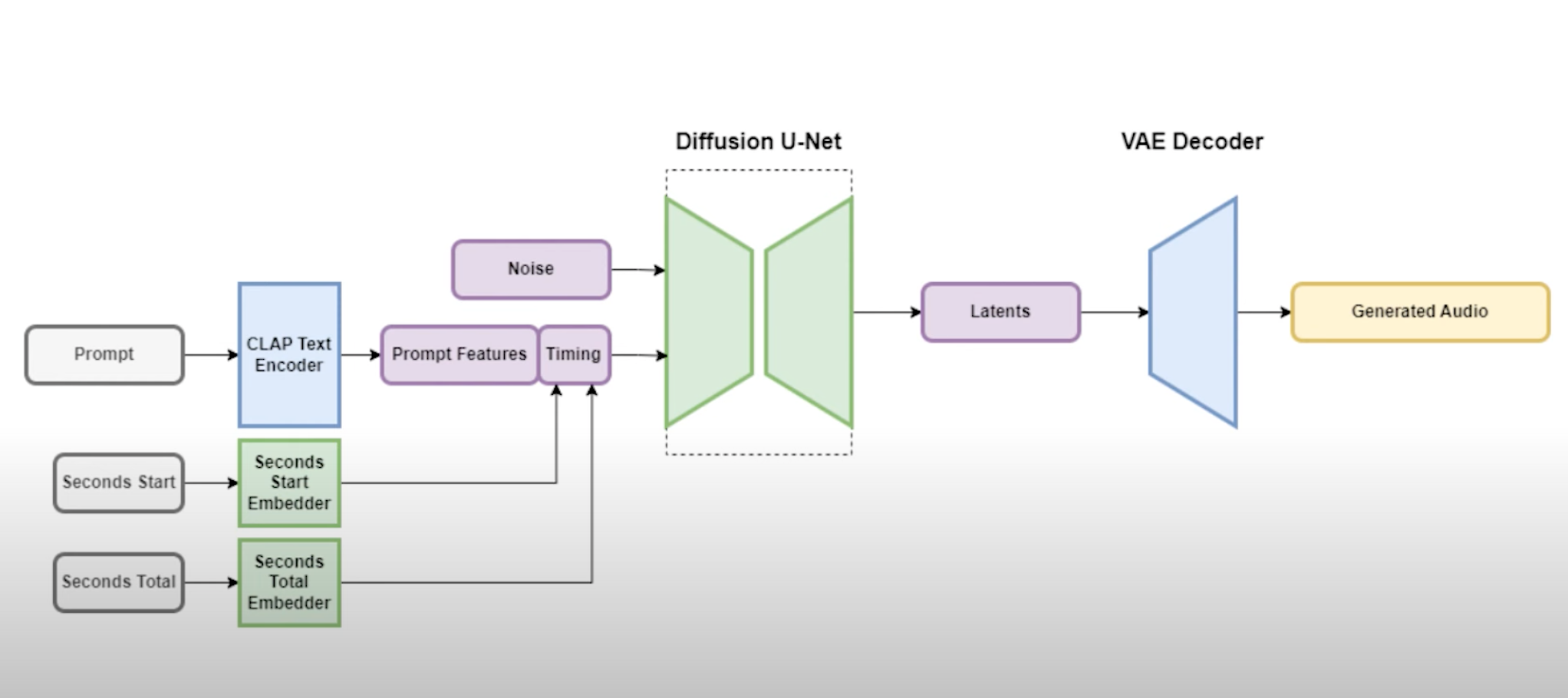
Stable Audio Open 1.0 is a powerful model that generates variable-length stereo audio (up to 47 seconds) at 44.1kHz from text prompts. It consists of three key components: an autoencoder that compresses waveforms into manageable sequence lengths, a T5-based text embedding for text conditioning, and a transformer-based diffusion (DiT) model that operates in the autoencoder’s…
-

Stable Video 4D
Introducing Stable Video 4D, stability AI’s Latest Model for Dynamic Multi-Angle Video Generation. Key Takeaways: How It Works Users begin by uploading a single video and specifying their desired 3D camera poses. Stable Video 4D then generates eight novel-view videos based on the specified camera angles, providing a comprehensive, multi-angle perspective of the subject. These generated…
-

Stable Audio Open Paper
StabilityAI excited to announce the release of the research paper for Stable Audio Open! This open-weight text-to-audio model generates high-quality stereo audio at 44.1kHz from text prompts. Perfect for synthesizing realistic sounds and field recordings, it runs on consumer-grade GPUs, making it accessible for academic and artistic use. Details The research paper on Stable Audio…
-

How does AI Music Generator Work?
Artificial Intelligence has revolutionized various industries, and music creation is no exception. AI music generators are sophisticated systems that can compose, produce, and even perform music autonomously. These tools use complex algorithms and machine learning techniques to analyze existing music, understand patterns, and create new, original compositions. Basic Principles of AI Audio Generation AI music…
-

Stable Audio Open
Stable Audio Dev Team thrilled to introduce Stable Audio Open, an open source model designed for generating up to 47 seconds of audio samples and sound effects from text prompts. This model enables users to create drum beats, instrument riffs, ambient sounds, foley recordings, and various production elements. With the ability to produce audio variations…
-
Stable Audio Explained
Did you know AI can already create amazing music? Yes, that’s right. Not only can this be done in a research context or by coding it yourself, but also on a website where you can simply enter a quick text description of what you want and get a music sample. The best thing is that…
-

Suno vs Udio
In the realm of AI-driven music generation, three platforms stand out: StableAudio, Suno, and Udio. While StableAudio has its merits, many users find themselves choosing between Suno and Udio. This article delves into a detailed comparison of Suno and Udio to help you decide which might better suit your musical creation needs. Core Features and…
-
Stable Audio Review
In this article, we delve into the capabilities of Stable Audio 2.0 and compare it with Suno AI v3, offering insights into their unique features and how they cater to different music creation needs. Introduction to Stable Audio 2.0 Stable Audio 2.0 has recently launched, and it brings several promising features for music creators. While…
-

Stable Audio 2.0 Paper
The evolution of audio synthesis technology has reached a new milestone with the development of Stable Audio 2.0. This innovative approach leverages latent diffusion models to generate long-form, high-fidelity stereo audio from text prompts. This paper delves into the mechanics of this system, showcasing its efficiency and the revolutionary step it takes beyond its predecessors.…